
Hanabi AI 在舊金山公開推出 OpenAudio S1,號稱全球第一款「AI 聲優」:它不只是讀稿機,而是一位可以在毫秒間調整情緒、語氣與節奏的虛擬演員。官方將這項突破形容為「語音從工具升級為表演」,這對影視、遊戲、Podcast 與所有需要說話的創作者而言,都是一次質變。
從 TTS 到 Voice Acting——關鍵三大轉折
-
真實情緒:S1 透過 40 億參數的端到端模型,學習超過 200 萬小時的多語音檔,能演繹「開心中帶一絲不安」這種複雜指令,並支援 (whispering with urgency) 等百種標記。
-
即時操控:官方實測延遲低於 100 ms,可在遊戲或直播中即刻變換腔調,不再受「先打字、後生成」的時差限制。
-
多語與多角色:原生支援 11 種語言,還能在一段對話中流暢切換角色與語系,保留音色一致性。
技術亮點
-
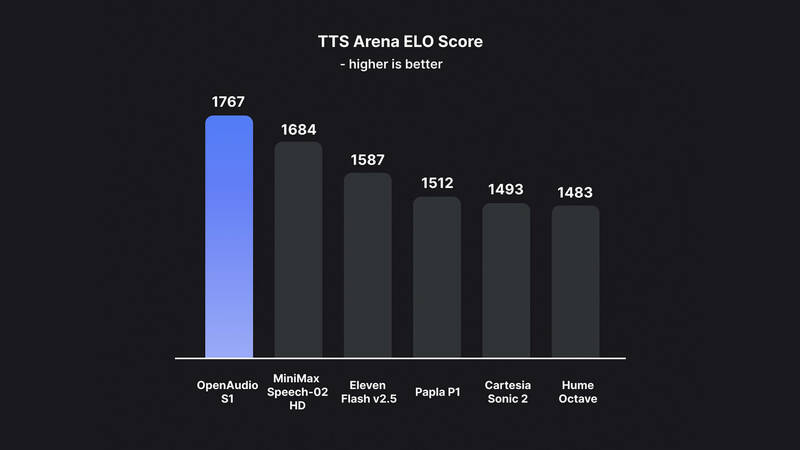
RLHF + 自研標註:團隊用自家 STT 模型自動標註情緒、語者與節奏,再以 4B 模型配合 Online GRPO 微調,取得 Hugging Face TTS Arena 人類主觀評分第一名。
-
語音複製:精準克隆說話者的韻律與音色,可為影片剪輯、劇集補錄或多媒體在地化大幅省時。
-
極速雲端 API:定價 15 美元/百萬 byte(約 1 小時語音),比同級對手平均便宜兩倍以上。
市場與應用
Hanabi AI 以四人 Z 世代創業班底,在 2025 年初即衝破年化 500 萬美元營收,月活用戶從 5 萬翻至 42 萬,代表「AI 聲優」已不只是 demo,而是具備商業價值的解決方案。S1 可望在以下場景掀起革命:
-
遊戲配音:NPC 對話可因玩家選擇即時改變情緒,帶來沉浸式劇情。
-
影視後期:臨時換角或補錄情緒,可直接輸出與原演員相符的音質。
-
串流直播:VTuber 或數位分身能即時改變情緒,強化互動張力。
-
教育與無障礙:以地道口音+情境語氣,打造更人性化的教學與輔助工具。
與競爭者的差異
現行市面熱門服務(如 ElevenLabs、OpenAI TTS、Cartesia)在延遲或情感細膩度仍有不足;S1 以更低延遲和全面情緒控制勝出,並在 Hugging Face 基準測試的表現、WER/CER 與主觀聽感全面領先。S1 目前提供免費公測 Playground,讓創作者無痛試玩;正式版的 120 美元年費更貼合獨立工作者的預算。
關於 Hanabi AI——把「開源魂」變成商業火箭
Hanabi AI 在 2024 年於舊金山成立,由開源社群名人 Shijia Liao 領軍,核心團隊僅四位 Z 世代工程師,卻立志顛覆語音生成的玩法——「聲音不只是輸出,而是一場表演」。創辦人早年參與 So-VITS-SVC、GPT-SoVITS、Bert-VITS2 等熱門專案,累積了對語者韻律與情感建模的深厚功力,也因此贏得開源社群的高度信任。這股「開源 DNA」後來成了公司研發與招募的護城河。
Hanabi AI 營運架構分成兩大支柱:OpenAudio 研究室專注突破模型極限(S1 即出自此處),Fish Audio 則把黑科技包裝成人人可用的雲端服務。短短四個月,靠著 Fish Audio 的早期產品,年化營收從 40 萬美元衝到超過 500 萬,月活用戶也從 5 萬扶搖直上 42 萬,證明「AI 聲優」不只是酷炫實驗,而是可規模化的生意。
Fish Audio——把實驗室黑科技送進瀏覽器
如果 OpenAudio S1 是一顆引擎,那 Fish Audio 就像放大器,讓創作者無痛踩下油門。平台目前已累積 20 萬+ 聲音模型庫,並獲得 150+ 位國內外 KOL 實戰背書,從 Podcast、VTuber 到互動小說都在用。
產品線涵蓋 TTS、Voice Cloning、STT,再加上 13 國語言跨語系輸出、一鍵 Voice Agent SDK 與 < 100 ms 延遲 API,無論要做遊戲 NPC 臨場對話或是自動客服都能即插即用。更重要的是,官方定價 15 美元/百萬 byte 的「均一價」策略,直接把門檻打到學生也能負擔。Fish Audio 也積極佈局生態系:今年 3 月與開源 LLM 平台 Dify 合作推出插件,讓開發者能在自家聊天機器人一鍵導入高擬真語音;接下來還計畫開放 WebRTC SDK,支援即時語音串流。
資料來源:Businesswire、Open Audio

![[教學] 合成器入門教學 – 總複習](https://digilog.tw/uploads/post/cover/126/thumb_webp_Synth-Modular.webp)



















![CLOUD [開封展示品出清] Cloudlifter CL-2 麥克風前級](https://digilog.tw/uploads/product/cover/3757/thumb_webp_Sales_260701_4.webp)



討論區
目前尚無評論